


Résumé de l'article par ChatGPT :
"Cet article présente une méthode d'amélioration continue appelée Kaizen et montre comment la Data Science peut être utilisée pour l'appliquer. La méthode Kaizen se compose de six étapes : la définition d'un objectif clair, l'analyse de la situation actuelle, la recherche de solutions, la mise en œuvre, la mesure des résultats et la standardisation. La Data Science peut aider à chaque étape, en fournissant des données pour comprendre la situation actuelle, en proposant des solutions basées sur des modèles prédictifs, en mesurant les résultats et en établissant des standards pour maintenir les améliorations. L'article donne un exemple concret de l'application de la Data Science dans le cadre de la méthode Kaizen."
Introduction
Sur les différents projets de Data Science sur lesquels j’ai travaillé, une constante a été l’évolution des méthodes pour itérer sur un algorithme existant : comment prioriser des expériences entre elles dans un cadre rempli d’incertitudes ?
Les cas d’école de Machine Learning, comme la fameuse compétition Kaggle sur les survivants du Titanic, sont souvent des use case simplifiés à l’extrême pour lesquels une approche brute force permet de trouver la solution. Dans la vraie vie d’un Data Scientist, les degrés d’incertitude sont bien plus nombreux, incluant par exemple la qualité de la donnée en entrée, les sources de données exploitables ou même la possibilité de résoudre le problème posé. Des contraintes en temps, de capacité de calcul s’ajoutent aussi à ces incertitudes, produisant un environnement où choisir et prioriser des expériences n’est pas trivial.
En parallèle, en collaborant avec des équipes de développement web et mobiles, j'ai pu observer des méthodes scrum rodées et super efficaces pour aller plus vite et améliorer la qualité des produits développés.
Pourquoi n’avons-nous pas d’équivalent en Data Science ? Les incertitudes citées ci-dessus y sont pour beaucoup. Dans ce post, j’aimerai vous proposer une méthode inspirée du PDCA (Plan Do Check Act), le Kaizen 6 steps pour donner un cadre à vos itérations en Machine Learning.
Le Kaizen 6 steps : qu’est-ce que c’est ?
La méthode du Kaizen 6 steps, initialement développée dans l’industrie automobile chez Toyota, se déroule en 6 étapes :
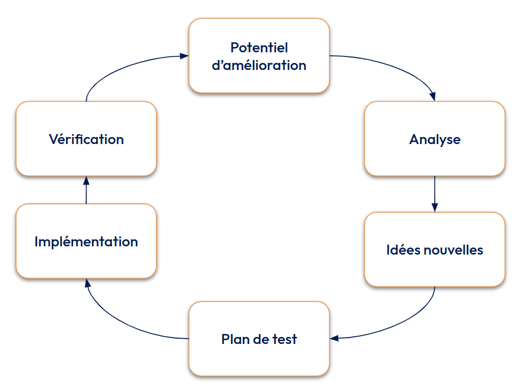
Les étapes du Kaizen 6 Steps
- Définir le potentiel d’amélioration ou trouver la métrique que l’on veut améliorer. De manière générale, cette étape est souvent la plus complexe. Dans le cadre d’une itération sur un algorithme existant, un bon choix de potentiel d’amélioration est la métrique business finale que le modèle vise à améliorer.
- Analyser la méthode actuelle : c’est l’étape qui est souvent manquante dans les flux d’itérations classiques de Data Science. Cette étape consiste à trouver les facteurs qui impactent la métrique de la première étape. Ici il ne s’agit pas de trouver comment ni de proposer des solutions, mais uniquement de valider ou invalider la pertinence d’un facteur. Dans le cadre d’un algorithme de Data Science, un facteur peut être le learning rate utilisé pendant l’entraînement, ou le volume des données pendant l’entraînement.
- Générer des idées nouvelles : une fois les facteurs validés, cette étape consiste à générer des idées concernant ces facteurs pour améliorer notre métrique de départ, rien de sorcier ici. Une estimation du ROI de chaque idée permet ensuite de prioriser ces idées : quel est le gain attendu ? Quel est l’effort à déployer pour l’implémenter ? Une question additionnelle pertinente dans le contexte de la Data Science est aussi : à quel point avons-nous confiance que cette idée aboutira ? Elle permet justement de prendre en compte l’incertitude liée aux itérations sur des modèles de Data Science.
- Préparer un plan de test de l’idée retenue : souvent oubliée, cette étape a pour but de lister et trouver des contre-mesures aux externalités négatives d’une idée. Par exemple, si nous avons retenu à l’étape précédente l’idée d’augmenter la volumétrie du dataset d’entraînement, un bon test est de vérifier la scalabilité de la pipeline d’entraînement.
- Implémenter l’idée retenue : just do it !
- Vérifier les résultats obtenus : pour s’assurer de l’impact sur le problème initial et le contrôle des externalités négatives listées à l’étape précédente.
Le kaizen est un cycle, dès l’étape 6 atteinte, vous pouvez repartir sur les étapes précédentes pour tester une nouvelle idée et continuer à améliorer ! Le kaizen, c’est aussi une activité d’équipe qui permet de réunir dans la même pièce et pour un temps long de deep work l’équipe au complet.
La puissance de la méthode Kaizen 6 steps dans le contexte de la Data Science réside dans l’étape d’analyse, qui permet de dégager de nouveaux facteurs et a pour but de les tester le plus rapidement possible, sans avoir nécessairement besoin de faire un cycle d’itération complet sur le modèle. Cycle qui peut se révéler extrêmement coûteux tant en temps de développement qu’en temps d’entraînement, par exemple dans le contexte de gros modèles de deep learning.
Success Story en Data Science: relancer l’amélioration d’un modèle LightGBM
La théorie c’est bien joli me direz-vous, mais est-ce que ça marche ?
Récemment, j’ai appliqué cette méthode avec une équipe dont la performance du modèle LigthGBM stagnait depuis plusieurs semaines. Malgré une dizaine d’itérations, la performance du modèle n’avait pas bougé depuis trois semaines.
A la suite du Kaizen 6 steps, deux apprentissages ont rapidement émergés :
- Le premier, qui peut paraître trivial, est que réunir l’ensemble de l’équipe Data Science autour de cette analyse a permis de dégager et de faire fuser des idées nouvelles. En 2h, l’équipe a proposé 19 hypothèses de facteurs, dont 12 ont été validées.
- Le deuxième, plus technique, est que certains de ces facteurs ont pu être validés ou invalidés sans avoir à refaire un cycle d’entraînement du modèle. En effet pour les hypothèses liées à l’impact d’une catégorie de features, une analyse des shap values produites avec le modèle actuel a permis d’orienter les itérations. Finalement, nous avons obtenu un gain d’un point d’AUC en travaillant sur le feature engineering des données en entrée du modèle.
L’analyse de facteurs ne permet pas de faire des raccourcis à tous les coups, mais se demander si une méthode simple et rapide ne permettrait pas de tester nos hypothèses en Data Science peut parfois nous faire gagner un temps précieux.
Un autre point d’attention est qu’il reste toujours délicat d’estimer l’impact relatif d’un facteur par rapport à un autre : pour cela il faudra tester !
Pour finir
Le Kaizen 6 steps est une méthode venue du Lean et applicable à une multitude de problématiques, en Data Science ou ailleurs. Au sein de la Data Science, elle peut aussi bien être utilisée pour améliorer les performances d’un modèle qu’à l’amélioration de l’environnement de travail des Data Scientists, en s’attaquant par exemple à la réduction du temps de run de leurs pipelines d’entraînement.
Son avantage principal dans le cadre d’itérations sur un modèle de Data Science est de prendre du recul sur les facteurs qui influencent sa performance. Et cela fonctionne encore mieux en équipe : si vous pouvez réunir autour de la table d’autres personnes qui auront de la connaissance sur le problème, comme des Data Analysts ou des Data Engineers pour les deux premières étapes, les idées de facteurs et d’amélioration seront souvent multipliées !
Vous souhaitez échanger sur l’amélioration de vos modèles de Data Science ? Contactez-nous !

